KI-basierte Literaturrecherche in der Labormedizin: Assistenz für die Wissenschaft
DOI: https://doi.org/10.47184/td.2025.01.01Große Sprachmodelle – auf Englisch Large Language Models – verfügen mittlerweile über erstaunliche Fähigkeiten. Doch wie können sie genutzt werden, um die Literaturrecherche in der Laboratoriumsmedizin auf eine neue Stufe zu heben? Dieser Beitrag beleuchtet die kurze Geschichte dieser Werkzeuge, zeigt die Möglichkeiten der Literaturrecherche mit Large Language Models auf, stellt konkrete Applikationen sowie eine Literaturrecherche-Pipeline vor und diskutiert die Potenziale und Risiken.
Schlüsselwörter: LLMs, Natural Language Processing, Halluzinationen, KI-Agenten
Der Wissenszuwachs in der Laboratoriumsmedizin schreitet im Zeitalter von Genomik und Proteomik, personalisierter Diagnostik und Therapie, digitalen Gesundheitslösungen, maschinellem Lernen, neuen Seuchen und vielem mehr so rasant voran, dass es schwerfällt, den Überblick über die aktuellen Entwicklungen zu behalten. Eine gründliche und effiziente Literaturrecherche ist daher unerlässlich, um auf hohem wissenschaftlichem Niveau die bestmögliche Patientenversorgung zu gewährleisten. Herkömmliche Methoden der Literaturrecherche, sprich das manuelle Durchsuchen großer Datenbanken wie PubMed oder Google Scholar, sind jedoch zeitaufwendig und mühsam. Seit der Veröffentlichung des großen Sprachmodells (Large Language Model; LLM) ChatGPT im Jahr 2022 haben sich künstlich intelligente Werkzeuge rasant weiterentwickelt. Nun gibt es die ersten LLM-basierten Tools, die die Rechercheprozesse revolutionieren könnten, indem sie große Mengen an medizinischer Literatur in kürzester Zeit finden, analysieren und relevante Informationen unter Angabe der Quellen extrahieren.
Kurze Geschichte der Sprachmodelle
Die Wissenschaft, die sich mit der sprachlichen Interaktion zwischen Mensch und Computer befasst, wird als Natural Language Processing (NLP) bezeichnet. Als Querschnittsdisziplin der Künstlichen Intelligenz (KI), der Computerwissenschaften und der Linguistik hat sie das Ziel, Computern das Verstehen, Interpretieren und Generieren von natürlicher Sprache – in der Regel also Alltagssprache – zu ermöglichen. Es entfällt die Kommunikation über eine Übersetzungsebene in Form einer Programmiersprache.
Um dieses Ziel zu erreichen, wurden in der Geschichte des NLP verschiedenste Algorithmen aus dem Bereich der regelbasierten Systeme, des maschinellen Lernens oder des Deep Learning mit mehrschichtigen neuronalen Netzen genutzt. Bereits 1906 wendete Andrey Markov die von ihm entwickelte Markov-Kette in Form sogenannter „n-Gramme“ an, um aus den vorhergehenden Wörtern eines Satzes das jeweils nachfolgende Wort vorherzusagen. 1950 publizierte Claude Shannon seinen Aufsatz „The Mathematical Theory of Communication“ [1], mit dem er heute noch relevante Prinzipien der Sprachmodellierung begründete.
Neben den wahrscheinlichkeitsbasierten Sprachmodellen wurde auch an regelbasierten Ansätzen gearbeitet. So entstand 1966 mit „ELIZA“ ein erster Chatbot („Plauderroboter“), der mithilfe einfacher Regeln ein psychotherapeutisches Patientengespräch simulierte. Zu Beginn der 1970er-Jahre begann der erste „KI-Winter“, in dem sich der Fokus von den wahrscheinlichkeitsbasierten neuronalen Netzen in Richtung regelbasierter Systeme verschob. Erst zu Beginn des 21. Jahrhunderts rückten neuronale Netze wieder in den Fokus des Interesses, da nun ausreichend Trainingsdaten und Rechenkraft sowie neue Algorithmen zur Verfügung standen, um selbstlernende Computersysteme zu trainieren.
2001 stellten Bengio et al. eines der ersten Sprachmodelle auf Basis eines neuronalen Netzes vor [2]. Über die Recurrent Neural Network Language Models (RNNLM) und die Long Short-Term Memory Networks (LSTM) kam es letztendlich zur Weiterentwicklung der heute so aktuellen, vortrainierten Transformer-Modelle (Pretrained Transformers; PT).
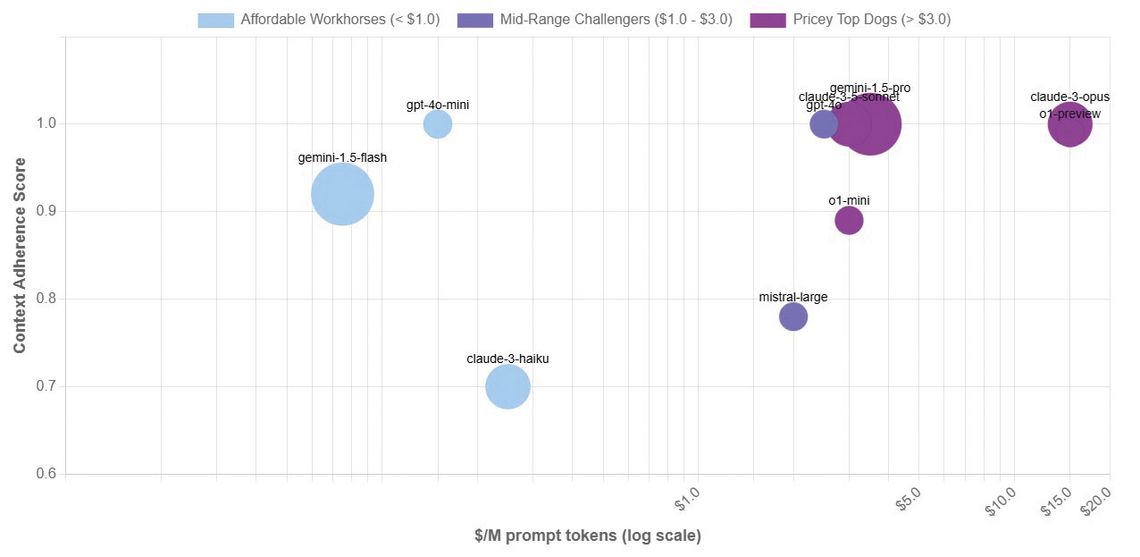
Abb. 1: Übersicht über Sprachmodelle mit langer Kontext-RAG (40.000 bis 100.000 Tokens). Die Größe der Kugeln repräsentiert die mögliche Token-Länge des Kontexts. Die Farbe veranschaulicht den Preis in Dollar pro eine Million Tokens im Prompt. Auf der Y-Achse ist der Context Adherence Score aufgetragen. Dieser wird mittels der ChainPoll-Methode zur Detektion von Halluzinationen gebildet. Je höher dieser Score ist (Maximum ist 1), desto mehr basiert die Antwort alleine auf dem Inhalt des Kontexts (der Quellen für RAG). Je geringer der Score, desto mehr „halluziniert“ das Modell [8].
Bei diesen Modellen unterscheidet man grob zwischen unidirektionalen (= Decoder; Ziel: Sprachgeneration, z. B. GPT [Generative Pretrained Transformer]), bidirektionalen (= Encoder; Ziel: Sprachverständnis, z. B. BERT) und Sequence-to-Sequence-Modellen. Die GPT- und BERT-basierten Modelle haben sich in den vergangenen Jahren zu den leistungsfähigen Modellen entwickelt, die die KI-Szene heute dominieren.
Wo stehen wir heute?
Nachdem ChatGPT erstmals für die Öffentlichkeit zur Nutzung freigegeben worden war, registrierten sich innerhalb von nur fünf Tagen über eine Million Menschen, um das LLM zu testen. Es handelte sich dabei um eine verbesserte Version des GPT3.5-Modells (veröffentlicht im März 2022). Mittlerweile steht die Version GPT4o1 zur Nutzung bereit, und GPT4o3 („o2“ gibt es aufgrund der Namensähnlichkeit zum Telekommunikationsanbieter O2 nicht) ist bereits angekündigt. Auch andere Big Tech Player haben in der Zwischenzeit ihre Modelle vorgestellt und stetig verbessert.
Bei Google wird aktuell das Gemini-1.5-Modell mit zusätzlichen Fähigkeiten ausgestattet, und Gemini 2.0 steht als „Vorschau“ im Google-Bezahlmodell bereits zur Verfügung. Meta hat mit seinem Llama-3.1-Modell in verschiedenen Größen (8B, 70B, 405B) den Weg des (Pseudo-)„Open Source“ gewählt (wobei nur die Modelle, nicht jedoch die Trainingsdaten „Open Source“ sind) und Llama 3.3 70B angekündigt. Das Anthropics-„Claude“-Modell liegt aktuell in der Version 3.5 („sonnet“) vor. Hugging Face, eine Online-Community für Modelle aller Art (Computer Vision, Natural Language Processing, Audio usw.) listet mittlerweile über 1,2 Millionen veröffentlichte KI-Modelle.
Inzwischen sind einige der Modelle auch in der Lage, multimodal zu arbeiten, das heißt, über Mediengrenzen hinweg Aufgaben im Bereich Sprache/Text, Bild, Video, Audio, Programmierung und Übersetzung zu bearbeiten. Schaut man sich exemplarisch das Absolvieren des deutschen medizinischen Staatsexamens an, so liegt hier nach aktueller Studienlage GPT4.0 mit 93,1 % richtigen Antworten im M1 und 94 % richtigen Antworten im M2 klar an der Spitze (zum Vergleich: Gemini 1.5 Pro mit 74,8 % in M1 und 65,5 % in M2) [3]. Da sich die großen Tech Player wie Microsoft (OpenAI, die Firma hinter ChatGPT und GPT4o1, gehört zu großen Teilen Microsoft), Google und Amazon auch im medizinischen Bereich immer stärker aufstellen, wird in Zukunft noch mit spannenden Entwicklungen der LLMs für das Gesundheitswesen zu rechnen sein.
Werkzeuge für die Literaturrecherche
Vor allem im Bereich der Literaturrecherche gibt es einige sehr interessante Werkzeuge – eine Auswahl ist in Tab. 1 zusammengestellt.
Tab. 1: Überblick über KI-Tools zur Literaturrecherche (in alphabetischer Reihenfolge).
Tool | Typ | Einsatzmöglichkeiten | Zugang |
|---|---|---|---|
Connected Papers | KI-Suchmaschine | Darstellung von Zusammenhängen zwischen Publikationen; Erweiterung einer vorhandenen Literatursammlung; vertiefende Recherche | |
Consensus | KI-Suchmaschine | Formulierung einer Fragestellung; initiale Recherche; Inhalte der gefundenen Publikationen gegenüberstellen („Consensus-Meter“) und zusammenführen | |
Elicit | KI-Suchmaschine | Initiale Recherche mit Fokus auf wissenschaftlichen Studien; Erstellung zusätzlicher Spalten für spezifische Fragestellungen, deren Antworten direkt aus den Studien extrahiert werden | |
Gemini Deep Research (Google) | KI-Suchmaschine | Initiale Recherche auch über wissenschaftliche Quellen hinaus (Artikel, Videos und Websites) zur Erstellung von Zusammenfassungen | |
Humata | KI-Chatbot | Tiefergehende Recherche in ausgewählten Publikationen | |
NotebookLM (Google) | Multimodaler KI-Chatbot | Generierung von Briefing-Dokumenten, FAQs, Studienhilfen, Zusammenfassungen und interaktiven Podcasts aus multimodalen Quellen (PDF, Google Docs, eigene Notizen, YouTube-Videos, Links etc.) | |
Open Knowledge Maps | KI-Suchmaschine | Initiale Recherche zur automatischen Gruppierung von Publikationen in Subgruppen | |
Perplexity | KI-Suchmaschine | Initiale tagesaktuelle Recherche im Internet mit Quellenangabe (nicht spezialisiert auf wissenschaftliche Quellen) | |
Research Rabbit | KI-Suchmaschine | Erweiterung einer vorhandenen Literatursammlung (ähnliche/früher/später erschienene Publikationen); Visualisierung als interaktiver Knowledge Graph; Literaturrecherche im Team möglich | |
Semantic Scholar | KI-Suchmaschine | Initiale Recherche; vertiefende Recherche an einzelnen Publikationen; Themen über längeren Zeitraum beobachten (Dashboards, Feed und Topics) | |
StormAI [4] | KI-Suchmaschine | Forschungsprojekt der Uni Stanford; initiale Recherche und Zusammenfassung der Ergebnisse; weitergehende Ergründung des Recherchethemas („Co-Storm“-Modus) |
Die Möglichkeiten reichen von der initialen Literaturrecherche anhand eines Überbegriffs über die Visualisierung der Zusammenhänge einer Literatursammlung bis hin zu einem „Chat mit einer Publikation“, um deren Inhalte tiefgründiger aufzuarbeiten und zu verstehen. Nachfolgend soll beispielhaft eine Literaturrecherche-Pipeline, wie ich sie benutze, erläutert werden.
Recherche-Pipeline
Die im folgenden Abschnitt erläuterte Recherche-Pipeline stellt nur eine Möglichkeit dar, die verschiedenen KI-basierten Recherchetools zu nutzen. Sie erhebt keinen Anspruch auf Vollständigkeit. Auch wenn die generierten Outputs von erstaunlicher sprachlicher Qualität sein können, sollten die Ergebnisse immer kritisch eingeordnet werden. Denn auch wenn man nun scheinbar „das Wissen der ganzen Welt gegen sich hat“, gilt: Vertrauen Sie Ihrer eigenen Expertise mehr als derjenigen eines Chatbots. Wenn Ihnen Dinge unplausibel erscheinen, dann sollten Sie die als Quelle angegebene Literatur prüfen. Der von mir genutzte Prozess ist in Tab. 2 dargestellt.
Tab. 2: Arbeitsschritte zur Nutzung eines KI-basierten Recherchetools.
Arbeitsschritte | Tool und Output |
|---|---|
Initiale Recherche | StormAI und Gemini Deep Research Output: Jeweils eine Zusammenfassung zur Beantwortung meiner Recherchefrage unter Angabe der Quellen |
Weiterführende Recherche | ResearchRabbit Output: Finden weiterer für die Fragestellung relevanter Publikationen und wenn möglich Download der relevanten Publikationen als PDF |
Zusammenführung und tägliche Arbeit | NotebookLM Output: Erstellung eines Notebooks zum Thema mit allen relevanten Quellen (Publikationen als PDF, Websites [z. B. Labor und Diagnose 2020 Online-Version], eigene Dokumente, Videos etc.) sowie Erstellung eines Briefingdokuments, von FAQs, einer Studienhilfe, einer Timeline oder eines Podcasts zum Hören unterwegs |
Zur Demonstration habe ich ein YouTube-Video erstellt, das frei zugänglich ist [5].
Vor- und Nachteile der LLM-basierten Recherche
Auch wenn die LLM-basierte Recherche enorm viel Zeit für eine initiale Recherche einspart, so müssen auch die Nachteile der KI-gestützten Suche betrachtet werden (Tab. 3).
Tab. 3: Potenziale und Risiken der LLM-basierten Literaturrecherche.
Potenziale | Risiken |
|---|---|
Hohe Geschwindigkeit beim Finden neuer Publikationen in der initialen Recherche | Es werden auch Publikationen gefunden, die für die Frage keine Relevanz besitzen (Nachbearbeitung notwendig). |
Schnelle Generierung von Kurzzusammenfassungen | Fehler bei der Erstellung von Zusammenfassungen („Halluzinationen“) |
Visuelle Darstellung von Zusammenhängen zwischen Publikationen | Finden von falschen Zusammenhängen, wenn Metadaten einer Publikation nicht richtig/gepflegt sind (Namensfehler etc.) |
Möglichkeit der Verarbeitung verschiedenster Quellentypen (Multimodalität) | Hoher Energieaufwand des Betreibens der Modelle mit entsprechend hohem CO2-Fußabdruck |
Zugänglichkeit der Information auch in anderen Formaten (Podcast über den Inhalt einer Publikation etc.) | Bias in den Trainingsdaten (Nachweis von linguistischem Rassismus [6]). Es ist bislang unklar, ob Auswirkungen auf die Literaturrecherche (z. B. zu Publikationen in Populationen von People of Color) bestehen. |
Tiefgründige Interaktionen (Chat) mit einer Publikation zum tieferen Verständnis | IT-Sicherheit (Prompt-Injection-Attacken [7] etc.) |
Ein zentrales Problem der LLMs sind die sogenannten „Halluzinationen“, das heißt die Generierung von Text, der zwar grammatikalisch korrekt und flüssig erscheint, der aber faktisch falsch oder unsinnig ist. Die Ursachen für Halluzinationen sind vielfältig und unter anderem von der Qualität der Trainingsdaten und der Architektur der Modelle abhängig. LLMs können Informationen aus verschiedenen Quellen kombinieren, dabei aber gleichzeitig Fakten verfälschen oder neue Informationen erfinden, die nicht in den Trainingsdaten enthalten waren. Um dieses Problem zu adressieren, wurden verschiedene Strategien entwickelt. Eine der am weitesten verbreiteten Strategien ist die Retrieval Augmented Generation (RAG), bei der das LLM zur Beantwortung von Fragen auf eine (ggf. kuratierte) Wissensdatenbank zugreifen kann und seine Antwort somit nicht allein auf den Inhalt der Trainingsdaten stützt. Weitere Strategien sind der Einsatz hybrider Systeme (Kombination mit regelbasierten Systemen), die Implementierung von Echtzeit-Feedback-Systemen sowie die Überprüfung und Annotation der Inhalte durch Menschen sowie Tools zur Erklärbarkeit des Modell-Outputs.
Zusammenfassend ist zu sagen, dass die „Halluzinationsrate“ der Modelle in den vergangenen Monaten stark abgenommen hat. Im Hallucination Index 2023 [8] kann man sich über die aktuelle Performance der Modelle informieren. Letztendlich stellt sich aber die Frage, ob man den Halluzinationen jemals Herr werden wird [9].
Was kommt als Nächstes?
Auch wenn sich die Zukunft nicht voraussagen lässt, so sind die weiteren Entwicklungen doch schon am Horizont sichtbar. Die Big Player unter den LLM-Providern werden große Anstrengungen unternehmen, um die Halluzinationsrate vor allem im medizinischen Bereich auf ein Minimum zu senken, da das Gesundheitswesen für die Big-Tech-Welt als einer der größten Zukunftsmärkte identifiziert wurde.
Die nächste Entwicklungsstufe, deren Anfänge bereits gemacht sind, werden sogenannte KI-Agenten (AI Agents, Agentic AI) sein, die klar vorgegebene Aufgaben selbstständig und automatisiert erledigen. Dabei generieren sich die Modelle die Eingabeaufforderungen (Prompts) selbst; das Modell gibt sich also selbst Anweisungen. Für den Bereich der Wissenschaft wurde zum Beispiel Agent Laboratory vorgestellt – ein LLM-Agent, der den gesamten Prozess der Forschung (Literaturrecherche, Planung der Experimente und Schreiben der Reports) unterstützt [10].
Nachdem ein Mensch nun keine Programmiersprache mehr beherrschen muss, um mit Computern zu kommunizieren, wird man in Zukunft nur noch die Hauptaufgabe definieren müssen, und die Zwischenschritte wird ein entsprechendes Modell von alleine definieren und ausführen (wie z. B. der Rechercheplan bei Nutzung von Gemini 1.5 Deep Research).
Satya Nadella, der aktuelle CEO von Microsoft, ging in einem Interview sogar so weit zu sagen, dass in Zukunft die Zwischenebene zwischen Datenbank und Output, also die Software, die wir tagtäglich bedienen (z. B. Excel, Power BI, Tableau, R, Python etc.), aufgrund der LLMs entfallen wird. Man werde dem LLM sagen, was es tun soll, und es wird sich selbst die Daten aus den Datenbanken aggregieren, die Analysen durchführen und die Ergebnisse in der jeweils gewünschten Form (Dashboard, App, Dokument, Präsentation, Video, Audio etc.) präsentieren. Ob Herr Nadella damit recht hat?
